The decisions the Raft paper leaves open, and the bugs that follow when you get them wrong.
I spent a few weeks building a distributed key-value store backed by a custom Raft consensus implementation in Go. This is not a post about how Raft works. The paper covers that.
This is about the decisions that the paper does not make for you. The places where Raft tells you what must happen, but not how to structure the code that makes it happen. The tradeoffs I made, including a few I made without realizing there was a tradeoff to make.
The repo is here if you want to follow along. What follows assumes a rough idea of how Raft works.
The problem with fsync
Raft requires that before a follower acknowledges an AppendEntries remote procedure call (RPC), the new log entries must be on disk. Not in the OS write buffer. On disk. That means fsync.
The naive approach is inline: receive entries, write, fsync, then reply. Simple to reason about. The problem is that fsync takes a few milliseconds even on a good SSD, and during those milliseconds your Raft mutex is held. Every other operation on that node is blocked: incoming RPCs, outgoing heartbeats, log reads, everything.
Batching helps. Instead of fsyncing on every entry, accumulate a few and sync once. That improves throughput but still leaves you with the question of when exactly to sync, and how to tell a specific waiting RPC handler that its entries are now safe.
I ended up with a dedicated persister goroutine. The core idea is to separate deciding what to write from actually writing it. State changes happen under the Raft mutex. The persister goroutine picks up whatever has accumulated, writes to disk outside the mutex, then signals back that the write is done.
Three condition variables share a single mutex:
cm.applyCond = sync.NewCond(&cm.mu) // new committed entries ready to apply
cm.persistCond = sync.NewCond(&cm.mu) // new entries need writing to disk
cm.syncCond = sync.NewCond(&cm.mu) // entries are now durableEach one signals a different event to a different goroutine. The persister's core loop follows one pattern: hold the mutex to read state and build a work list, release it for all I/O, re-acquire to signal completion.
// snapshot entries to write while holding the lock, then release before touching disk
cm.mu.Unlock()
cm.storage.AppendLog(entry) // disk write
cm.storage.Sync() // fsync, outside the mutex
cm.mu.Lock()
cm.persistedIndex = targetIndex
cm.syncCond.Broadcast() // wake RPC handlers waiting for durabilityThe syncCond.Broadcast() at the end is what unblocks the follower's AppendEntries handler. That handler has been waiting on syncCond since it appended the entries, and it will not reply Success: true to the leader until this signal arrives. Durability before acknowledgment is the whole point.
Here is the full sequence for a single write, from the moment Submit() is called on the leader to the moment the follower replies:
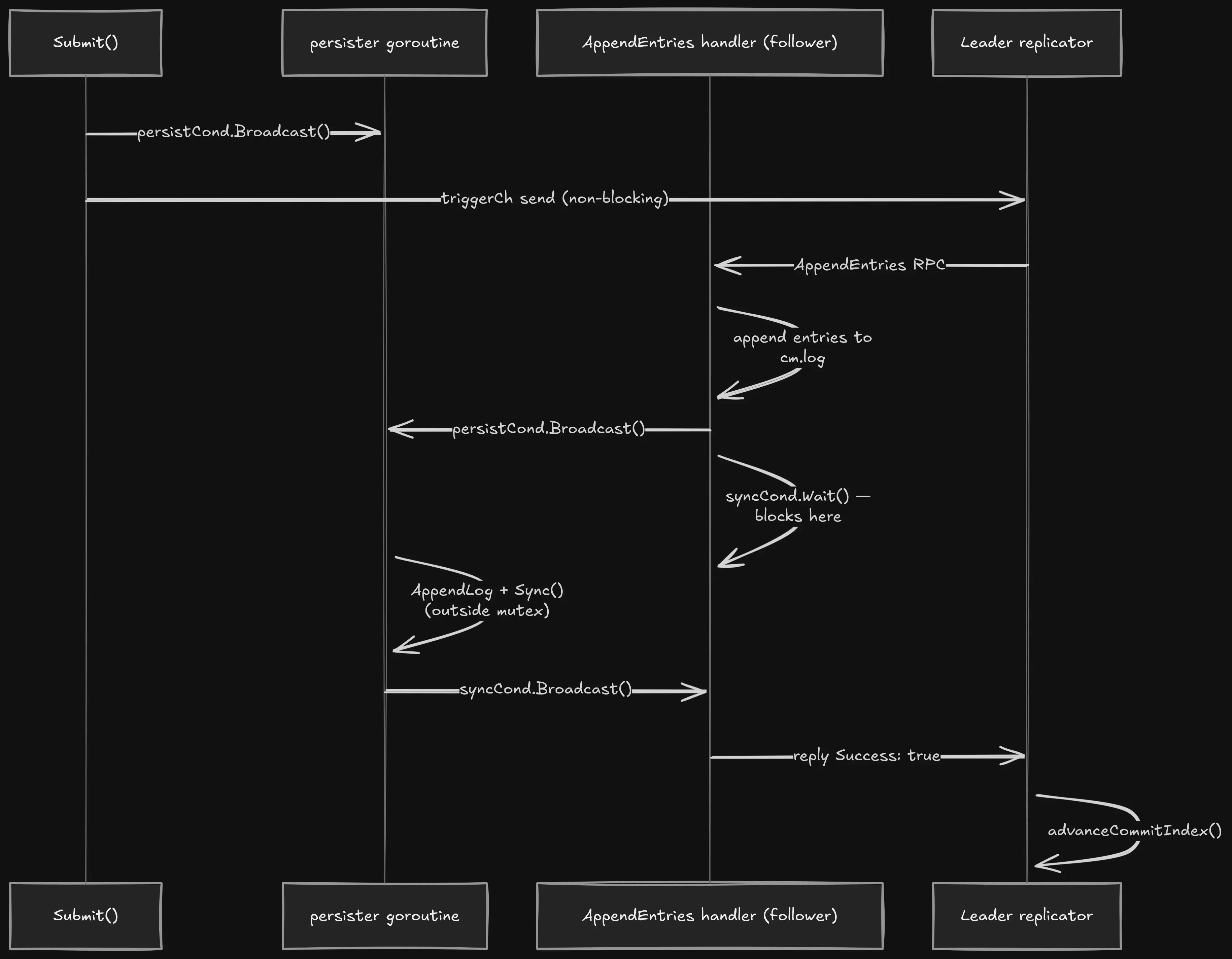
One thing that surprised me when reading this code later: persistedIndex is not a monotone counter. When a follower receives conflicting entries and truncates its log, persistedIndex gets set backwards and the persister rewrites the entire log from scratch. It is correct behavior, but it violates an assumption you might carry from simpler systems where "how far we have persisted" only ever goes forward.
Reads are harder than writes
Writes are simpler. A write is committed when a majority of nodes have it durable, and the client waits for that before getting a reply.
Reads are trickier. The Raft paper gives you two options, and both have a cost. Option one: treat a read like a write. Submit a read barrier to the log, wait for it to commit, then return the value. This guarantees the read sees everything committed before it. The cost is a full replication round-trip on every GET, even when nothing has changed.
Option two: leader leases. If the leader has received heartbeat acknowledgments from a majority of followers within the last X milliseconds, it must still be the leader. A new leader cannot have been elected without those followers timing out first. So the current leader can serve reads from local state, no round-trip needed.
The lease check looks like this:
validAcks := 1 // count self
now := time.Now()
for _, ackTime := range cm.recentAcks {
if now.Sub(ackTime) < 150*time.Millisecond {
validAcks++
}
}
if validAcks*2 > len(cm.peerIds)+1 {
return nil // quorum heard from recently, safe to read
}
return fmt.Errorf("leader lease expired")The assumption buried here is that X milliseconds on the leader's clock must be at least as long as one full election timeout on the followers' clocks. If a follower can time out and start an election before the lease expires, the old leader might serve a read after it has already been deposed.
Here, the lease window is 150ms and the minimum election timeout is also 150ms. Heartbeats go out every 50ms. The relationship looks like this:
Time (ms)
0 50 100 150 200 250 300
|---------|---------|---------|---------|---------|---------|
Heartbeats
●---------●---------●
0 50 100
Leader Lease
├─────────────────────────────┤
0 150
Election Timeout Range
├─────────────────────────────┤
150 300
The safety margin is exactly zero. The strict < in the check (not <=) saves you at the exact boundary, but real schedulers have jitter and the election timer polls every 10ms. A follower that should fire at 150ms might fire at 160ms. A lease check at 155ms would still pass.
Re-election breaks this too. The map tracking when each follower last acked a heartbeat never gets cleared when a node steps down or wins a new election. A node that was leader in term 3, stepped down, and won re-election in term 5 inherits acknowledgment timestamps from term 3. If those timestamps are less than 150ms old, the re-elected node passes the lease check immediately, before sending a single heartbeat in the new term.
The lease is supposed to prove quorum in the current term. The timestamps it checks don't know what term it is. The fix is one line, clearing the map in startLeader(), but you only write that line if you understand what the lease is actually proving, not just that it involves checking timestamps.
The insight about write latency
My first mental model of the commit path was sequential: leader writes to its write-ahead log (WAL), sends to followers, waits for them to write to their WALs, then commits. Total latency equals the sum of two fsyncs.
That is not how it works.
The leader starts writing to its own WAL at the same time as it sends AppendEntries to followers. The commit happens when a majority reply. In a three-node cluster, that means the critical path latency is whichever of the leader's write or the one required follower's write takes longer, not their sum.
This has a direct consequence. A follower on a slow disk sets the write latency floor for the whole cluster whenever it is on the critical path. If a follower's fsync exceeds the 100ms RPC timeout, the leader gets an error and waits for the next heartbeat tick (50ms) before retrying. No immediate retry, no backoff. One node on degraded storage causes the leader to retry every 50ms indefinitely, and every client write stalls until the disk recovers.
The snapshot bug I wrote a comment on
When a node takes a snapshot, it writes two things to disk: the state machine data and the Raft metadata, which includes LastIncludedIndex, the log index the snapshot covers. These two files must stay consistent. If they drift, recovery applies the snapshot at the wrong index.
The SaveSnapshot function writes them in this order:
func (d *DiskStorage) SaveSnapshot(meta []byte, data []byte) error {
os.WriteFile("raft_snapshot", data, 0644) // state machine blob
os.WriteFile("raft_state", meta, 0644) // LastIncludedIndex
}The code that calls this has a comment: "Write snapshot before metadata to ensure recovery safety." That comment only considered one of two crash windows:
Crash window A : process dies before first write completes:
raft_snapshot: OLD data (covers index 100)
raft_state: OLD meta (LastIncludedIndex = 100)
→ Files agree. Recovery is safe.
Crash window B : process dies after first write, before second:
raft_snapshot: NEW data (covers index 200)
raft_state: OLD meta (LastIncludedIndex = 100)
→ Files disagree. Recovery applies state@200 at index 100.In window B, the node restarts, reads metadata saying the snapshot covers index 100, and restores KV state from a snapshot that actually covers index 200. Raft believes entries up to index 100 are the baseline. When this node rejoins the cluster, the leader sends entries 101 through 200 again. The follower accepts and re-applies them on top of a state machine that already processed those operations.
The correct fix is to treat the snapshot file as an atomic swap. Write the new snapshot to a temp file and rename it into place. On POSIX-compliant filesystems, rename is atomic: the file either has the old content or the new content, never a half-written state. The metadata is written after the rename, so crash window B becomes impossible.
Crash safety isn't just about write ordering. It is about mapping every crash point to the state a recovery process would find. The comment on this code only considered one crash point. That is the kind of gap you do not catch by reading your own code.
What the test suite actually tests
The failure injection tests can kill nodes, break individual network links asymmetrically, and pause election timers to simulate a zombie leader that cannot trigger re-election in the rest of the cluster.
These tests check availability: after a partition heals, a new leader is elected in a strictly higher term, and the partitioned leader could not commit writes without a majority.
What they do not check is whether the operations before, during, and after the partition were linearizable. A partitioned leader that serves stale reads violates linearizability. A node that applies the same log entry twice after snapshot corruption also violates it. Neither failure would be caught by a test that only checks whether a new leader was elected.
Porcupine takes a log of client operations and tells you if any valid linearizable execution could have produced that history. Without that, you're testing availability, not correctness. They're not the same thing, and correctness is harder.
What I would do differently
The timing constants bother me most. The lease window, minimum election timeout, and heartbeat interval have a required mathematical relationship: heartbeat < lease_window <= election_timeout_min. Violate it and you get stale reads with no error and no obvious symptom. Right now all three are raw integer literals scattered across three files with no shared definition and no startup assertion. They belong in one place with the constraint written out explicitly.
The snapshot write needs the atomic rename approach. One temp file and one rename eliminates crash window B.
The test suite needs a linearizability checker. Porcupine is straightforward to integrate and would have caught both the snapshot bug and the re-election lease race before a code audit did.
The KV store also needs command deduplication. Right now PUT accidentally behaves correctly on replay because overwriting a key with the same value is idempotent. Any non-idempotent operation would silently produce wrong results. Correctness by coincidence is not correctness.
Building Raft from scratch, you can't skip the details. Every decision forces you to understand why the protocol requires what it requires, and there are more decisions than the paper suggests.
The bugs here were not from misunderstanding Raft. They came from reasoning about each piece in isolation without following edge cases to the end. The snapshot bug required thinking about two crash windows, not one. The lease bug required asking what "recent acknowledgment" means across term boundaries. The test gap required asking what correctness actually means, not just availability. None of it felt like an open question while I was writing it. That's the thing, it only looks obvious after.